git clone https://huggingface.co/spaces/aadnk/faster-whisper-webui
cd faster-whisper-webui
uv venv
.venv\Scripts\activate.bat
set "CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8"
echo %CUDA_PATH%
uv pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118
uv pip install -r requirements.txt
uv pip install -r requirements-fasterWhisper.txt
uv pip install hf_transfer
cp config.json5 config.json5.bak
subl config.json5
"models": [
{
"name": "medium",
"url": "Simple_Speech_Recognition/modelsCache/faster-whisper-medium",
"type": "filesystem"
},
{
"name": "large-v2",
"url": "Simple_Speech_Recognition/modelsCache/faster-whisper-large-v2",
"type": "filesystem"
},
{
"name": "large-v3",
"url": "Simple_Speech_Recognition/modelsCache/faster-whisper-large-v3",
"type": "filesystem"
},
]
"input_audio_max_duration": -1,
"server_port": 7830,
"whisper_implementation": "faster-whisper",
"default_model_name": "medium",
"vad_parallel_devices": 0,
"auto_parallel": true,
"output_dir": "<output_dir>",
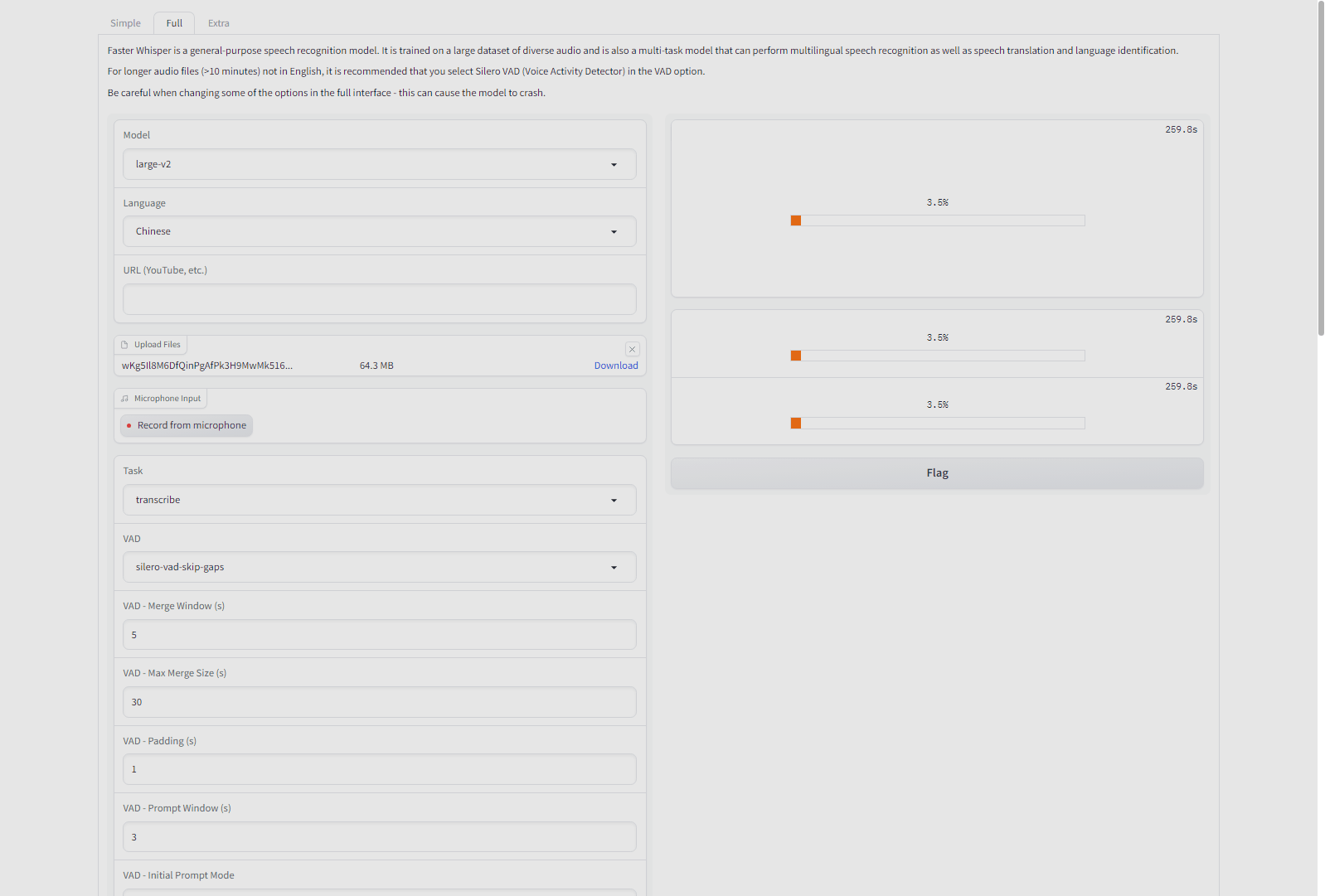
"language": "Chinese",
## As CLI
python cli.py --whisper_implementation "faster-whisper" --vad "silero-vad-skip-gaps" --auto_parallel true --vad_parallel_devices 0 --model "large-v2" --language "Chinese" --initial_prompt="对于普通话句子,以中文简体输出" --diarization_num_speakers 1 --auth_token <hf_token> --output_dir "C:/Users/User/Downloads" <input>
## As Web UI
python.exe app.py --input_audio_max_duration -1 --server_name 127.0.0.1 --server_port 7830 --whisper_implementation "faster-whisper" --default_model_name "large-v2" --vad_parallel_devices 0 --auto_parallel true --auth_token <hf_token> --output_dir "C:/Users/User/Downloads"